
What is search crawling?
Crawling is the process by which search engine robots (web crawlers, spiders) discover, crawl, and download content from various URL addresses. Not all URLs are automattically checked. You can choose to exclude some using information in the robots.txt file.
The crawler collects data about the webpage, including text, images or videos, and tries to understand its content as best as it can. It stores the obtained data in an index – a virtual database from which all search results then originate.
Why do you need your website to be crawled?
Without crawling and subsequent indexing, your website will not appear in the search results. This means you won’t show up on Google and potential customers will only come across your competitors’ sites when they enter a query.
Crawling and indexing problems may not affect the entire site. Sometimes only an important subpage can be missing or Google might be too slow to index new content.
For news sites, slow indexing is as big a problem as no indexing at all. If you write about the results of sports events or breaking news and this enters the index with a time delay, you clearly have an issue.
How does website crawling work?
The work of crawlers is precisely defined and consists of the following steps:
- URL Discovery: There are several ways in which crawlers learn about new pages. These include using sitemaps, previously searched websites or via internal and external links.
- Content download: When a crawler discovers a URL, it downloads its content, including HTML, images, and other media files.
- Indexing and extracting links: The crawler analyses the downloaded content and decides whether or not to include it in the index. It assigns the indexed URL a position in the search results for specific keywords. At the same time, it pulls links into the next crawl plan. Of course, it only focuses on those that are essential and correspond to the website’s guidelines.
- Prioritising URLs: Each URL that the crawler needs to revisit is listed and prioritised based on relevance and importance.
Why aren’t all pages indexed?
By crawling websites, the search engine, most often Google, constantly adds new pages to its index. In this way, it is able to constantly update the data with new content.
Google, of course, does not index all pages. You don’t even need it to index many (for example, subpages created by filtering, selected product variants or steps in the cart).
There is no indexing
The lack of indexing of a page is often related to a crawling ban of the given subpage specified in the robots.txt file. It is set using the “disallow” command. If you have subpages after the disallow command in your robots.txt, check whether you really want robots not to visit the page or whether it might be a mistake.
Do you want to know what is the state of your website? Generate exclusive PDF audit now.
How to optimise website crawling
You need a simple URL structure, easy-to-understand sitemaps, an internal and external linking network, and several other tools and tactics to increase the efficiency of website browsing. We will go through all of them step-by-step and demonstrate them using practical examples.
Optimise XML sitemaps
In order to organise the website for bots, you need a sitemap in an XML format, and we recommend this for every website that has more than 100 subpages. Ideally, you should be generating it regularly (and automatically) using plugins.
What does the sitemap look like and what does it contain?
At first glance, it looks like web content, but for robots. Thanks to it, they know which pages of the website are the most important. Sitemaps should only include those pages that you want to end up in the index.
In addition to the URL address, the sitemap should also contain the date of the last modification. This will enable the incoming robot to know which pages have changed since its last visit.
Pay attention to the crawl budget and web accessibility
Every website needs Google bots to regularly visit important subpages and detect new ones as soon as possible. However, the robot only has a limited computing capacity reserved for the web. How can you utilise it to your best advantage?
What is a crawl budget?
The search engine allocates a crawl budget to web pages based on the response from the server, the size of the website, the frequency with which you update the pages and the linking of pages (both internal and external). Simply put, Google crawls popular URLs much more frequently.
“The most essential tool for optimising crawling is definitely a well-configured robots.txt and a regularly updated Sitemap with a well-preset <lastmod> tag.
However, as SEO specialists, we must also monitor and ensure “browsing health”. This means eliminating 5XX status codes, soft 404s or chain redirects. FIially, we must not forget the daily bread of an SEO specialist, duplicate content,” reveals our SEO specialist Martin Gajdos.
Remove duplicate pages from your search
Duplicate content complicates web indexing. Duplication means that there are multiple URLs with identical or very similar content. Googlebot then cannot decide which page is the main one and may mistakenly assign the wrong value. This results in lower search positions.
For online stores, duplication is most often caused by product filtering, usually relating to the price. If the visitor moves the price by even one euro, a very similar page with almost identical content will likely be displayed, and duplication occurs.
In that case, you have to distinguish the URL address for each filter, set the canonicalization correctly or prohibit bots from browsing these pages in robots.txt.
Practical example: IBO
In the case of our partner, IBO, we were primarily tasked to solve the problem of technical SEO. Complications arose during the indexing process, when robots also crawled pages without much value.
The online store had more than 3 million indexed pages and 6 million non-indexed pages, most of which were duplicates from filtering.
We solved the problem by correctly setting the indexing rules for search engines.
For a website of such size, always consider the crawl budget (the computing capacity that the search engine allocates for processing the page) and its effective use.
We configured a robots.txt file that clearly set out the rules for robots. We also created separate sitemaps for product categories, individual products or sold out products. We excluded from indexing all subpages that are created when searching the web, when registering or when logging into an account.
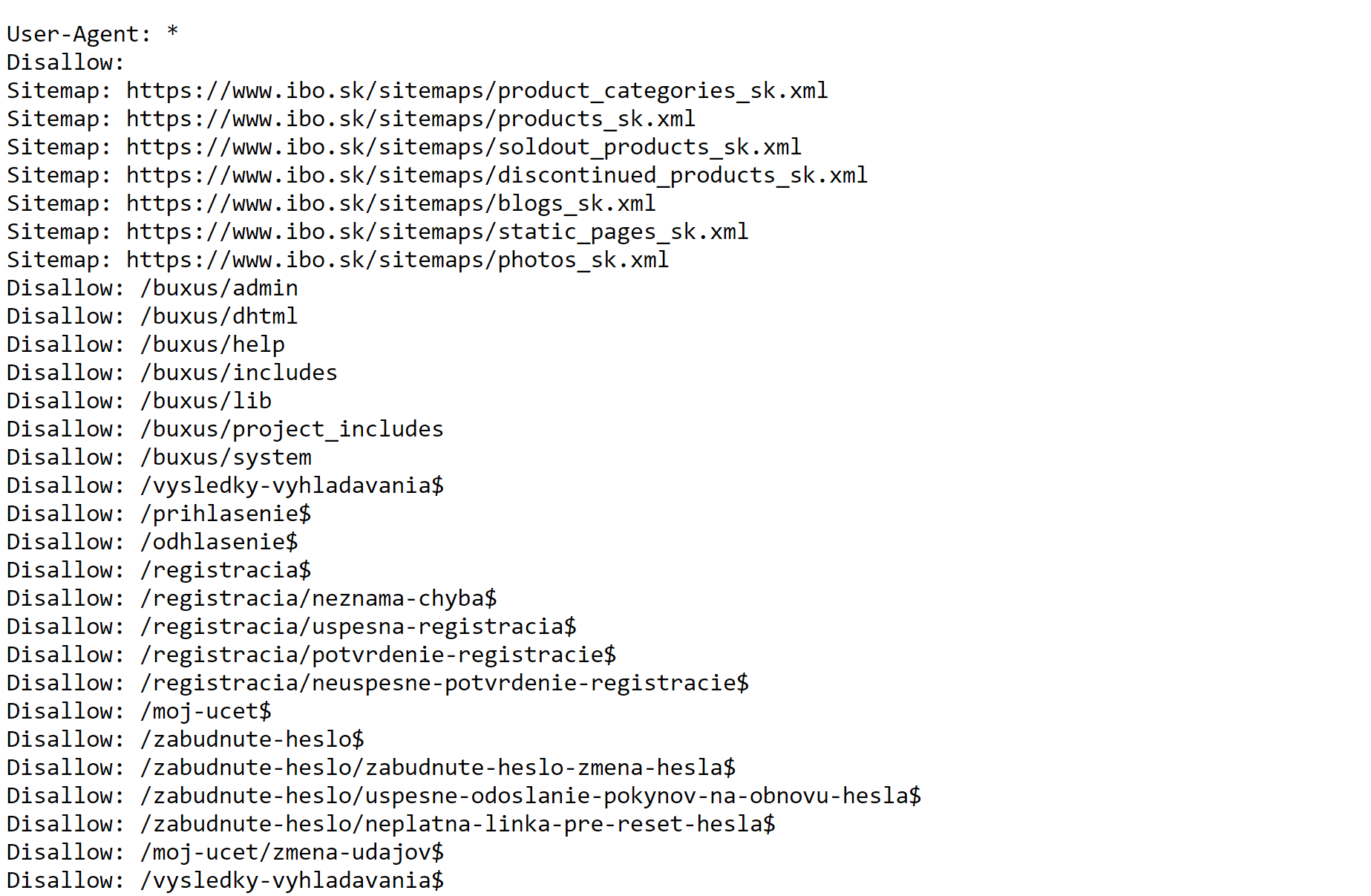
Robots.txt for the ibo.sk website, where we modified the indexing rules for Googlebots in line with the goals of the online store.
Along with editing the texts in the main categories, creating a blog, internal linking and quality content, we also managed to get IBO to an average of first position for all relevant phrases. Year-on-year, the number of impressions increased by 133% and organic traffic rose by 26%.
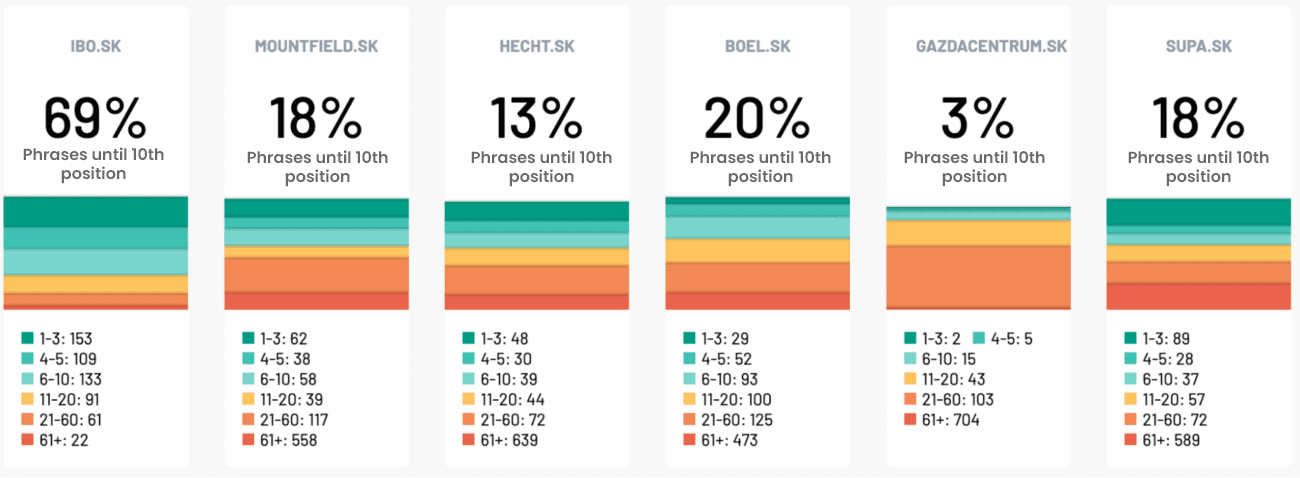
As many as 69% of tracked keywords appear on Google up to the tenth position. This places it several-fold ahead of the competition.
Support crawling with internal links
Internal links have a big impact on effective crawling. Optimise the structure of internal links on the website and ensure easy navigation and accessibility of relevant pages.
If you strategically link different websites, you will make it clear to the crawlers that page A is related to page B. At the same time, the search engine will have a better understanding of the content of the website and the inter-connection of the pages.
A great technique for building internal linking is topic clusters.
Remove content without value
Purge the website of low-quality, outdated or duplicate content that distracts crawlers from new or recently updated content. Merge similar content and use a 301 redirect.
Is your website not indexing properly?
Website crawling is a key aspect of SEO and affects the indexing of your content in search results. If your content is being indexed late, or you have a problem with duplicate subpages or crawl budget, we would be happy to help you.
Our team of SEO specialists has experience with both small and large online stores and can ensure that Google finds and correctly indexes all of the most important subpages.



